TFIDF Amazon Reviews Design Document
Why I Did This Project?
This project was an opportunity for me to learn about Natural Language Processing techniques and also learn to preprocess text data into trainable inputs for machine learning models.
Software Skills
-

Python
Programmed in Python
-
NLP
Understanding Natural Language Processing techniques
-
Machine Learning
sklearn Python library for ML
-

Data Preprocessing
Python Libraries: Pandas and Numpy
Project Description
This project is trains multiple Machine Learning models on Amazon Review data in order to predict if a given review is 1-5 stars.
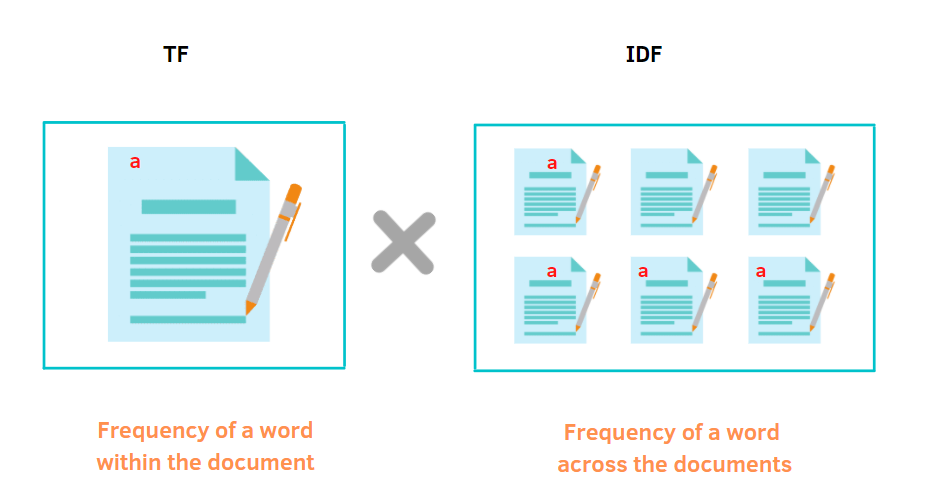
The project also utilizes TF-IDF (term frequency inverse document frequency) to convert text data into numerical vectors that the ML models can use for training.
ML Models: Perceptron, SVM, Logistic Regression, and Multinominal Naive Bayes
Steps:
Data Preprocessing:
- 1. Load Amazon Review Data
- 2. Filter data and remove any null data points
- 3. Randomly choose 20k data points from each rating of 1-5 stars
- 4. Concatenate the five datasets of 20k each
- 5. More data preprocessing/cleaning on words in dataset
- 6. Vectorize data with TFIDF
Machine Learning/NLP:
- 1. Split vector data into Train-Test split
- 2. Train each ML model on train data
- 3. Have each model predict labels for test data
- 4. Output Precision, Recall, F1-score on predictions